Java+MySQL+Redis高并发架构实践:缓存穿透、击穿、雪崩解决方案
引言
在当今互联网应用中,高并发场景下的性能优化是后端开发者必须面对的核心挑战。Java作为企业级开发的主流语言,MySQL作为最广泛使用的关系型数据库,Redis作为高性能缓存中间件,这三者的组合构成了经典的后端技术栈。当流量激增时,缓存层的稳定性直接决定了系统的可用性。本文将深入探讨Java+MySQL+Redis架构下的三大缓存问题——缓存穿透、缓存击穿、缓存雪崩,并结合实际代码示例给出可落地的解决方案。
一、缓存架构基础
1.1 为什么需要缓存
MySQL数据库虽然功能强大,但在高并发场景下存在天然的瓶颈:磁盘I/O开销大、连接数有限、复杂查询耗时长。以一个典型的电商应用为例,首页商品列表的QPS可达数万甚至数十万,如果每次都直接查询MySQL,数据库很快就会成为系统瓶颈。
引入Redis作为缓存层后,读操作的基本流程变为:
- 客户端发起请求
- 先查询Redis缓存是否存在数据
- 缓存命中则直接返回,缓存未命中则查询MySQL
- 将MySQL查询结果写入Redis并设置合理的过期时间
- 返回数据给客户端
1.2 典型的缓存读写模式
业界最常用的是Cache Aside(旁路缓存)模式:
// Cache Aside 读操作:先查缓存,缓存没有则查数据库
public Product getProductById(Long productId) {
String cacheKey = product: + productId;
String cachedJson = redisTemplate.opsForValue().get(cacheKey);
if (cachedJson != null) {
return JSON.parseObject(cachedJson, Product.class);
}
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(product), 30, TimeUnit.MINUTES);
}
}
// 写操作:先更新数据库,再删除缓存
@Transactional
public void updateProduct(Product product) {
productMapper.updateById(product);
redisTemplate.delete(product: + product.getId());
}这套模式看似简单,但在高并发场景下却隐藏着三个致命的缓存问题,下面我们逐一分析。
二、缓存穿透:请求穿透缓存直达数据库
2.1 问题描述
缓存穿透是指查询一个数据库中不存在的数据。由于缓存中也没有这条数据,每次请求都会穿透缓存直接打到数据库上。如果攻击者故意构造大量不存在的key发起请求,就会对数据库造成巨大压力。
2.2 解决方案
方案一:布隆过滤器(Bloom Filter)
布隆过滤器是一种空间效率极高的概率型数据结构,它可以判断一个元素「一定不存在」或「可能存在」。在查询缓存之前,先通过布隆过滤器判断key是否合法:
// 使用 Redisson 的布隆过滤器
RBloomFilter bloomFilter = redissonClient
.getBloomFilter(product:bloom);
bloomFilter.tryInit(100000L, 0.0001);
// 预热:将所有商品 ID 加入布隆过滤器
List allProductIds = productMapper.selectAllIds();
allProductIds.forEach(bloomFilter::add);
// 查询时先通过布隆过滤器校验
public Product getProductWithBloom(Long productId) {
if (!bloomFilter.contains(productId)) {
return null; // 一定不存在
}
return getProductById(productId); // 可能存在
} 方案二:缓存空值
当查询结果为空时,也将这个空结果缓存起来,并设置较短的过期时间(通常2-5分钟):
public Product getProductWithNullCache(Long productId) {
String cacheKey = product: + productId;
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
if (NULL.equals(cached)) return null;
return JSON.parseObject(cached, Product.class);
}
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(product), 30, TimeUnit.MINUTES);
} else {
redisTemplate.opsForValue().set(cacheKey,
NULL, 3, TimeUnit.MINUTES);
}
return product;
}实际生产环境中,建议组合使用布隆过滤器+缓存空值,形成双重防护。布隆过滤器拦截绝大多数非法请求,缓存空值兜底处理漏网之鱼。
三、缓存击穿:热点数据过期瞬间的高并发冲击
3.1 问题描述
缓存击穿是指某个热点key在过期的一瞬间,大量并发请求同时穿透缓存打到数据库。这与缓存穿透的区别在于:缓存击穿的数据在数据库中是真实存在的,只是缓存刚好过期了。
例如一个热门商品的详情页,缓存过期时间为30分钟。在第30分钟过期的那一刻,恰好有1000个用户同时访问,这1000个请求都会发现缓存失效,然后同时去查询数据库,可能导致数据库瞬时压力暴增。
3.2 解决方案:互斥锁(Mutex Lock)
核心思路是:当缓存失效时,只允许一个请求去查询数据库并重建缓存,其余请求等待或返回旧值。
方案一:Redis SETNX 实现分布式锁
public Product getProductWithLock(Long productId) {
String cacheKey = product: + productId;
String lockKey = lock:product: + productId;
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) return JSON.parseObject(cached, Product.class);
Boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, , 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(locked)) {
try {
cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) return JSON.parseObject(cached, Product.class);
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(product), 30, TimeUnit.MINUTES);
}
return product;
} finally { redisTemplate.delete(lockKey); }
} else {
Thread.sleep(50);
return getProductWithLock(productId);
}
}方案二:逻辑过期 + 异步更新
上面的方案在高并发下仍有性能损失(大量请求自旋等待)。更优雅的做法是使用「逻辑过期」:缓存永不过期(物理上),但在value中存储一个逻辑过期时间,后台异步刷新:
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
public Product getProductWithLogicalExpire(Long productId) {
String cacheKey = product: + productId;
String lockKey = lock:product: + productId;
String json = redisTemplate.opsForValue().get(cacheKey);
if (json == null) return null;
RedisData redisData = JSON.parseObject(json, RedisData.class);
Product product = JSON.parseObject(
JSON.toJSONString(redisData.getData()), Product.class);
if (redisData.getExpireTime().isAfter(LocalDateTime.now())) {
return product;
}
Boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, , 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(locked)) {
threadPoolExecutor.execute(() -> {
try {
Product dbProduct = productMapper.selectById(productId);
RedisData newData = new RedisData();
newData.setExpireTime(LocalDateTime.now().plusMinutes(30));
newData.setData(dbProduct);
redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(newData));
} finally { redisTemplate.delete(lockKey); }
});
}
return product;
}逻辑过期方案的优势在于:用户请求不会被阻塞,永远能拿到数据(哪怕是旧数据),而缓存的更新在后台异步完成。这在热点数据场景下尤为适用。
四、缓存雪崩:大规模缓存同时失效
4.1 问题描述
缓存雪崩是指在同一时刻,大量缓存key同时过期,或者Redis服务集群宕机,导致所有请求直接打到数据库,造成数据库压力骤增甚至崩溃。
常见的触发场景:
- 缓存预热不充分,同一批次加载的数据设置了相同的过期时间
- Redis实例宕机或网络故障
- 定时任务大批量刷新缓存,老缓存同时被清理
4.2 解决方案
方案一:过期时间加随机值
为每个key的过期时间加上一个随机偏移量,避免集中过期:
public void setWithRandomExpire(String key, Object value,
long baseMinutes, int randomRange) {
long actualMinutes = baseMinutes +
ThreadLocalRandom.current().nextInt(randomRange);
redisTemplate.opsForValue().set(key,
JSON.toJSONString(value), actualMinutes, TimeUnit.MINUTES);
}
// 使用示例:基础30分钟,随机偏移10分钟内
setWithRandomExpire(cacheKey, product, 30, 10);
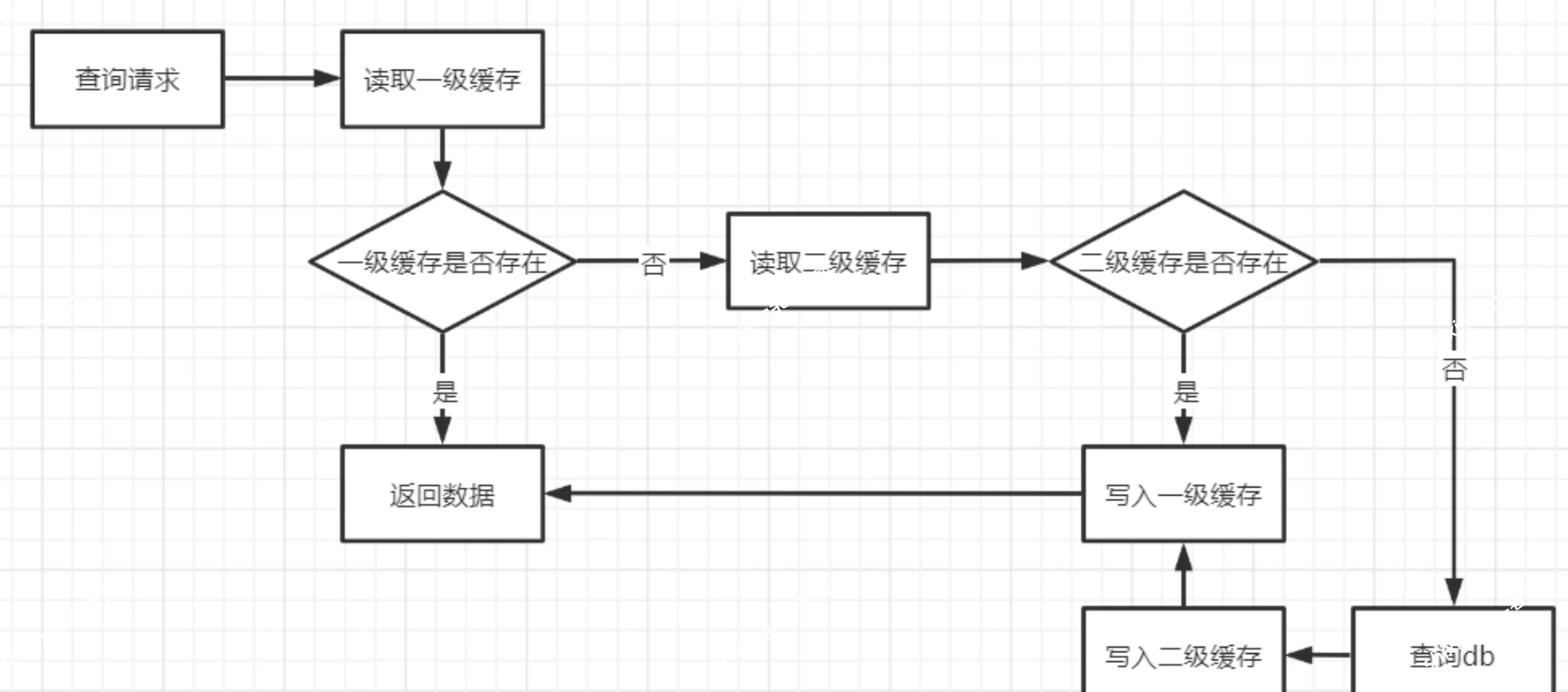
// 实际过期时间在30~40分钟之间随机分布方案二:多级缓存架构
在应用层也加一层本地缓存(如Caffeine),即使Redis宕机,本地缓存仍能支撑一部分请求:
Cache localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
public Product getProductWithMultiLevelCache(Long productId) {
String cacheKey = product: + productId;
Product product = (Product) localCache.getIfPresent(cacheKey);
if (product != null) return product;
try {
String json = redisTemplate.opsForValue().get(cacheKey);
if (json != null) {
product = JSON.parseObject(json, Product.class);
localCache.put(cacheKey, product);
return product;
}
} catch (Exception e) {
log.error(Redis异常,降级到数据库, e);
}
product = productMapper.selectById(productId);
if (product != null) {
localCache.put(cacheKey, product);
try { redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(product), 30, TimeUnit.MINUTES);
} catch (Exception ignored) {}
}
return product;
} 方案三:服务降级与熔断
当Redis集群完全不可用时,通过Hystrix或Resilience4j等熔断器实现服务降级:
@HystrixCommand(fallbackMethod = getProductFallback)
public Product getProductWithCircuitBreaker(Long productId) {
String json = redisTemplate.opsForValue().get(product: + productId);
if (json != null) return JSON.parseObject(json, Product.class);
return productMapper.selectById(productId);
}
public Product getProductFallback(Long productId) {
log.warn(缓存服务降级,直接查询数据库);
return productMapper.selectById(productId);
}熔断器可以在Redis故障时快速失败,避免大量请求积压导致数据库雪崩。
五、总结与最佳实践
针对Java+MySQL+Redis架构中的三大缓存问题,我们总结出以下最佳实践:
- 缓存穿透防护:布隆过滤器 + 缓存空值双重防护
- 缓存击穿防护:热点数据使用互斥锁或逻辑过期+异步更新
- 缓存雪崩防护:过期时间随机化 + 多级缓存 + 服务降级熔断
- 监控与告警:监控Redis命中率、慢查询、连接数等关键指标
- 容量规划:根据业务量合理规划Redis内存和集群规模
在实际生产环境中,建议将上述方案组合使用,形成立体的防护体系。同时,要结合具体的业务场景进行调优,例如:
- 对于秒杀场景,优先使用逻辑过期+异步更新方案
- 对于商品详情页,使用多级缓存提升响应速度
- 对于用户信息等读多写少的数据,适当延长缓存时间
缓存系统的优化是一个持续的过程,需要根据业务发展和流量变化不断调整策略。希望本文能为你在Java后端架构中的缓存设计提供有价值的参考。